
Want to scrape bulk data without getting blocked?
Want to scrape bulk data without getting blocked?

You must be eyeing some data on a competitor’s website.
You might think that you can get a competitive edge if you can get hold of this data.
However, you need the data not just once but regularly.
You want to scrape it but you are not sure if it’s legal to scrape web data.
Don’t worry; you are not alone.
A lot of people are not sure whether web scraping is legal or not.
Some people scrape the web data and don’t stop at anything.
Some others are not sure if getting product descriptions from an e-commerce site would invite legal trouble.
No worries.
To put the debate to rest, we have put together this blog that dispels all the myths regarding legality of web scraping.

When you are engaging in web scraping, you may not find it offensive or unethical.
However, if you find out that somebody else is scraping your website for a competitive advantage or financial windfall, you would not like it!
This is what it’s all about.
Web scraping is generally not carried out for harmless, academic purposes.
People think that web scraping is a process by which companies encroach upon their space and gain a competitive advantage for financial gains.
To put it more precisely, here’re the key points why people consider web scraping offensive and even unethical, bordering upon illegal:
In several subtle ways, web scraping annoys people and earns a poor reputation for itself. However, it’s ironic that everybody who finds web scraping offensive also needs web scraping equally badly!
Like it or not, it’s a data-driven world.
No matter what your field of operation is, you need access to tons of data. Without data, you cannot make any real progress.
If it is not possible to work or carry out business at an individual level without leveraging data, imagine the stakes for a multinational company.
Imagine that you are a billion dollar corporation and you are about to work out your marketing campaign. Can you just shoot in the dark?
Of course not!
You need something to base your policy and strategy.
This is where data comes in.
You would need reliable and latest data regarding your area of work.
This is where web scraping comes as a huge boon.
Not only that web scraping can automate the process, it can also make a lot of data available in no time.
Web scraping can relieve the burden of hunting for data as it can make it all available in one place. Moreover, while data is anywhere available on websites, it is not available in a usable format. Web scraping can extract the data in a format of your choice like Excel so that you can process it and use it the way you want.
There are various ways in which web scraping is a great help without which the digital world as we know it may come to a standstill.
As long as web scraping remains in the legal boundaries and procures the data you want, there should be no reason to term it offensive or illegal.
Let’s take a practical example to understand this. Craigslist sued a company called Instamotor for scraping its content to create their own listings and sending mails to Craigslist users for selling used cars.
Guess what happened next?
Instamotor was ordered to pay $31 million to Craigslist.
As you can see, it can get pretty nasty as a legal issue.
You might wonder how far it is legal and when it becomes illegal where you make yourself vulnerable to such lawsuits.
We have put together key points for you to find out how legal or illegal your web scraping exercise is.

As you can see in Craiglist issue, it was not so much about the data itself. But it is much more about the abusive access and use of the data.
This is where Computer Fraud and Abuse Act (CFAA) comes in. Craiglist got the upper hand because of this act. Under this act, an unauthorized use of data from a web page can be liable to legal action.
So while web scraping, you must ensure that you are not in violation of this act. Web scraping would be illegal if it is in violation of CFAA.
Tip #1 “Don’t violate the norms laid down in CFAA. Avoid the abusive access and use of data for business and financial gain.”
Copyright is a widely known concept.
However, you might wonder what it’s got to do with web scraping.
Well, when you scrape web data, you are accessing data which could be protected by copyright.
So if you scrape it and use for commercial purposes, it could invite legal trouble.
You may think that you are scraping public data and there’s nothing wrong with it. You are right to the extent that you scrape it. However, making commercial use of this data is not allowed under copyright laws. Therefore, if your web scraping leads to copyright violations, it would be termed illegal.
Tip #2 “Respect copyright and don’t scrape and use data protected by copyright.”
This one sounds less scary than the CFAA and Copyright Infringement. However, it is also equally serious legal issue.
Basically you know how trespassing is treated legally. You are not allowed to trespass on someone’s property.
Likewise, entering the prohibited space and behaving in an irresponsible manner on the digital platform is also not appreciated.
In terms of web scraping, it is offensive if you directly damage the website and its functioning in any way. While scraping web data, many people fail to see how their web scraping adversely affects the website and the server.
To expedite the processing of scraping the data, your scraper may make too frequent requests and slow down or bring down the server. This could qualify as the matter under trespass to chattel.
In any way, your web scraping must not affect the website and the server. If it does, you are exposing yourself to some legal trouble.
Tip #3 “Don’t enter the prohibited space and don’t violate the owner’s space and data.”
Well, there is something called Robots.txt which you must consider at the outset. In simple terms, it’s document that contains all the rules regarding how bots should interact with the website.
Some websites completely prohibit bots. If you are careful enough, you would get the message to stay away from such a site.
It also clarifies what the website considers “good behavior” when it comes to access, restricted web pages and frequency of crawling.
So if you want to play it safe legally, you must adhere to the norms laid down in Robots.txt. This is a clear indication what you must and must not do. As long as you follow the norms contained in it, you would be safe, legally!
Tip #4 “Follow the norms of Robots.txt and respect the terms described in it while scraping the web data.”
The strength of web scraping is also its weakness. The reason why web scraping is preferred is because of the speed with which it can fetch the data you want.
However, here’s the hitch. Websites don’t like such aggressive crawling and scraping of the data at such a fast clip.
This is why many websites specify the crawl-delay settings in order to slow you down. However, many people scraping data aggressively disregard this crawl rate and end up scraping in a way that either harms or upsets the site owners. This, in turn, can expose you to significant legal trouble.
Tip #5 “Don’t crawl in an aggressive manner. Follow a reasonable crawl rate of 1 request per 10-15 seconds. As long as you follow a reasonable crawl rate, you will be safe.”
Scraping data without considering the legalities of it in an aggressive fashion can get you in trouble.
Instead you can opt for a safer path like using an API. Most of the websites that you come across have already got an API for its users.
It would not be advisable to scrape data in an aggressive way when an API is available. The reason is that using an API puts you in a much better position.
As long as you use an API and don’t indulge in desperate efforts of scraping the data violating the norms, you will be legally safe.
Tip #6 “Most websites have got an API. Use API instead of scraping wherever provided.”
When it comes to scraping, people tend to cross the lines quite often. One such line that people cross is Terms of Service (ToS).
Websites create and store the data in a way that is protected from predatory scrapers. Terms of Service would state it quite clearly that there’s data on this site that they don’t want to allow anybody to scrape.
You might think that you are scraping the public data but if the Terms of Service prevents you from scraping it, you are crossing the line.
Scraping public data may not be strictly illegal but you have exposed yourself to a situation in which a company can initiate action against you if it wishes.
The bottom line is that you must respect the Terms of Service or be prepared for legal trouble!
Tip #7 “Follow and respect Terms of Service. If it explicitly lays down norms for web scraping, follow it in letter and spirit.”
The world of business has become so data-driven that companies are willing to go to any lengths to procure data. Since time is of the essence, companies want the data right away.
In an effort to beat the competitors, they would take undue risks and scrape away at a great pace disregarding the norms and rules.
One such example is the way scrapers hit the servers repetitively.
Humans don’t access a website so frequently and websites are designed for such a human pace of accessing websites.
So when you hit the servers too frequently, it may happen that the server will crash or at least slow down to extent that it cannot efficiently load web pages.
It gives the website owner the right to initiate legal proceedings against you considering the fact that your efforts have harmed their website in a willful way.
Tip #8 “Maintain time gap between two requests. Don’t be too aggressive in your scraping efforts.”
On the other hand, you exercise restraint and don’t hit the servers too frequently, you will be able to scrape the data as long as you want. It will enable you to scrape the web data and avoid any legal ramifications as well.
As a smart Internet user, you must learn to distinguish between public content and private data.
Websites keep some data available for public use and allow anyone and everyone to access it. However, there’s some data on the website which is not for public access.
You would know it very well. But if you knowingly go beyond the public content and scrape data that is not open to the general users, you will be asking for trouble.
For instance, if it requires logging in, it means it is not for public access. You need to stay away from such data that you can get only after logging in.
If you violate this basic norm and extend your scraping exercise beyond the public content, you may invite the legal trouble. However, if you stick to the public content, you will be safe and will be able to scrape as long as you want without having to worry about legal issues.
Tip #9 “Access the public data only. Don’t go beyond the public data. It will lead to violation of copyright etc.”
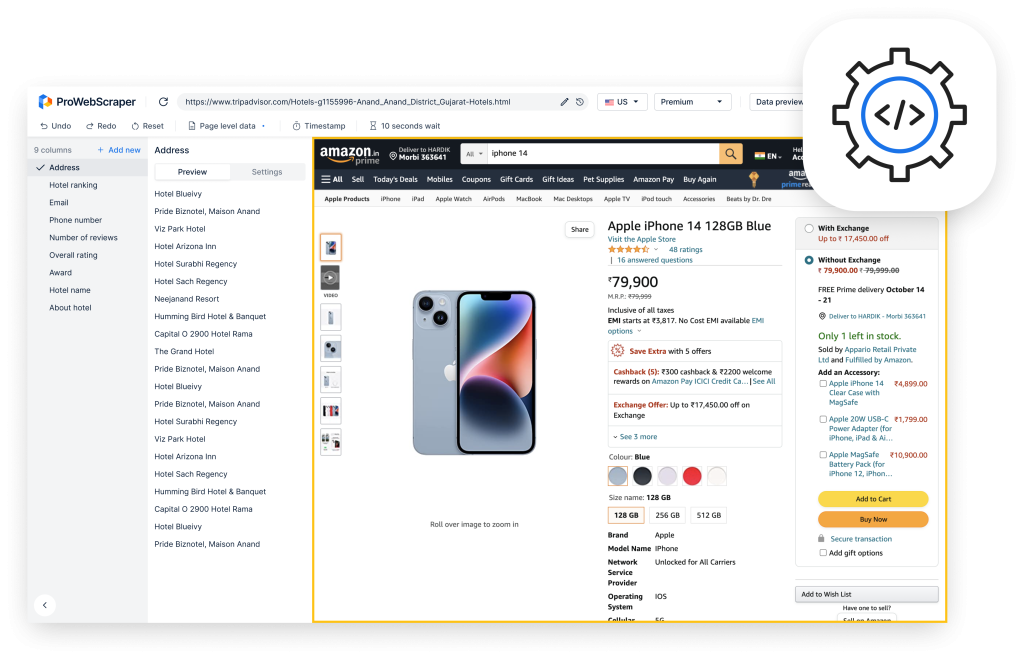
The question is not whether you will scrape the web data or not scrape it because web scraping is inevitable.
There’s no other fast and efficient way to extract web data you need for the decision making and growth of your business.
The question, however, is how to scrape web data without inviting legal trouble. To avoid legal problems, you need to maintain a fine balance between the tendency to scrape under all circumstances and the respect for the website’s norms.
If you violate any of the norms that the website has laid down in different places, you are exposing yourself to legal complications.
On the other hand, if you scrape data in a smart way that does not harm the website in any way, you can go on scraping the data without having to worry about legal issues.
Hope this blog will help you steer clear of the legal problems and enable you to make great scraping decisions.
Scrape away but be safe and respect other’s websites!


[…] way around the captchas using different services available. However, you do need to understand the legality of scraping data and whatever you are doing with the […]
[…] To start with, every website has its robots.txt. It contains rules and regulations regarding how the bots should interact with the website. As long as you follow these rules, web scraping can remain a legal exercise. […]